抽空实现了下计算机视觉中最基本的“Hello World”,Mnist数据集。
这里我用的是Jupyter Notebook,它比较方便快捷,适合进行快速debug,当然缺点就是自建库的调用不太方便。我将在GitHub上传该项目,欢迎star:)
一、数据集处理
我用的是从百度网盘下载的(应该没有侵权吧233)的Mnist数据集,差不多长这个样子:

对,这是一种特殊的压缩格式,网络上现在很多都是直接用Pytorch下载,而我认为其实很多情况下都需要处理一些奇怪的数据类型,理想的“即插即用”的情况实在太少了。可见数据处理是门学问(只对我而言哈哈)。
这个格式可以用np.load()函数装载,读入后会以列表的形式装着四个子文件夹,分别为测试集与训练集的图像数据和标签,那么我们就可以都用numpy来表示这些数据了;之后,为了让这些数据能加速,需要转化成张量(Tensor)放入GPU,于是转化成张量的torch.from_numpy()也是必不可少的。这部分代码如下:
1 | #加载数据集与预处理 |
这里有个图像增加通道,是因为我发现读入的数据只有三维(训练集是60000×28×28,600000是batch size,表示有600000张图片堆在一起处理),而后续处理需要增加一个channel,变成(60000×1×28×28)。
之后,要把数据和标签一一对应起来,这需要用到Torch中的Dataset类方法,我们需要继承这个父类并编写getitem()、len()、add()方法(这个方法可以不写)和初始化init()。我们希望这个类能够把x和y封装在一起,便于后边操作。我这里是这么写的:
1 | #数据封装,方便之后网络处理 |
后面调用只要用
1 | train_data = Mnist_Dataset(x_train, y_train) |
来封装数据即可。事实上这里我也只是依样画葫芦,具体的原理需要查阅其他文献,不过我发现大量的Dataset重构中,init()基本都是用来传入路径的,而getitem()主要用来对图像进行transform(如reshape操作等)并返回图像及label。
最后,我们需要一个DataLoader来装载Dataset,这个DataLoader是一个迭代器,将Dataset划分为若干个Batch,并打乱数据集(如果shuffle=True的话),在后续训练时,每次取出迭代器中的一个Batch进行训练,若后续利用优化器进行梯度下降,则实现了小批量梯度下降。当然,如果你的Batch设成1或者设成数据集的大小的话,也就实现了随机梯度下降或小批量梯度下降。
代码看这里:
1 | #将数据放入数据加载器 |
二、网络及其定义
查阅相关论文,找到LetNet这一经典网络,我们继承nn.Module类,书写LetNet这一类:
1 | #定义LeNet网络 |
可以看出,LetNet由俩函数组成,第一个是集成父类和定义网络结构的init函数,而另一个定义了前向传播,这里面关于nn.Conv2d等是Torch库的写法,不再赘述。
在使用网络时,我们需要传入一个四维张量(batch×channel×长×宽),这个网络自动输出10类手写体(0~9)每一类的概率。这里是代码,其中inputs是(64×1×28×28)的张量。
1 | outputs = model(inputs) |
三、训练
我们已经定义了数据集与网络,现在首先要做的是定义损失函数与优化器,这里选的损失函数是交叉熵损失,因为交叉熵损失不用将标签转化为one-hot类型,而优化器用的是经典的Adam。需要注意的是,我们定义了一个model,这个model就是LeNet(),但是为了让它能在GPU上加速,要让它放在cuda上(没有的话就cpu咯):
1 | #指定使用的具体设备 |
最后,我们开始训练:
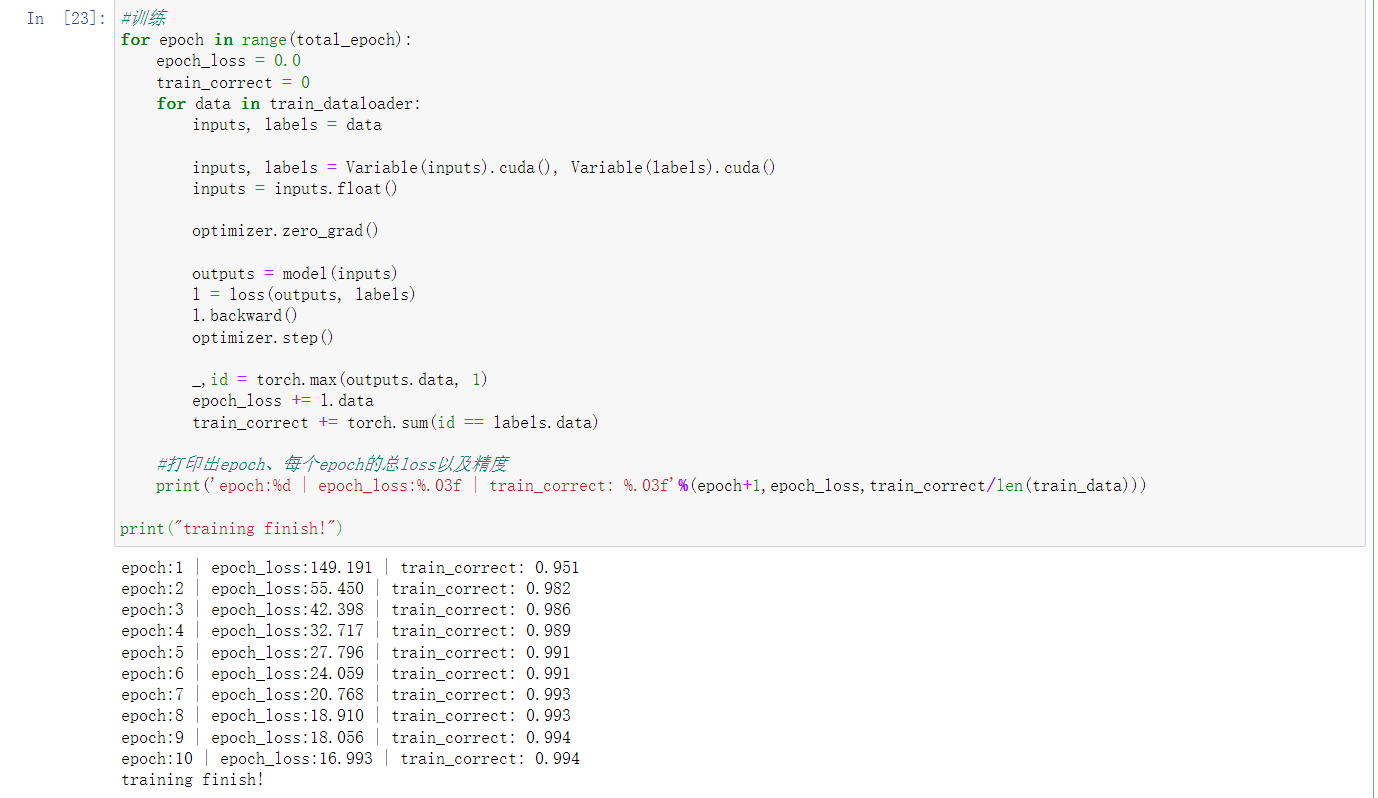
1 | #训练 |
这里其实有点问题,每个epoch的loss是每个batch loss的平均值,这里用的是累积值。
Variable(inputs).cuda(), Variable(labels).cuda()用于将inputs和labels放到GPU上,没有这个会显示Tensor的类型不一致而报错,inputs = inputs.float()也是为了让数据一致,你可以试试去掉会有什么事情发生。
对了,反向传播前要将优化器梯度清零,所以有optimizer.zero_grad();而optimizer.step()是为了更新l的值。
为了判断正确率,这里设置输出最大的outputs的值作为最终的分类结果,并和label进行对比,正确则train_correct加一,然后就是老生常谈的输出了,这块输出是这样的:
训练完后保存模型,在测试时加载模型的代码长这样:
1 | #保存训练模型 |
四、测试
这里和训练基本没区别,只是要导入测试集、没有epoch以及没有反向传播而已,祭出代码:
1 | #对测试集进行测试 |
最终准确率为98.7%,loss为9.380,效果还是很好的。
五、总结
其实感觉没啥好总结的,但是做出手写体识别还是挺有成就感的,之后大概会更新一些其他模型吧,哈哈。那么今天就到这里了,再见大家。