神经网络类型:BP(back propagation)神经网络
隐藏层:1(含神经元:3,偏置项独立)
激活函数:y=x
正则化:无
迭代次数:300
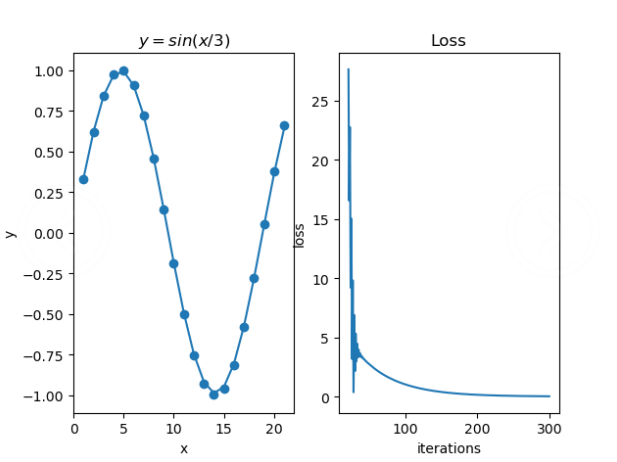
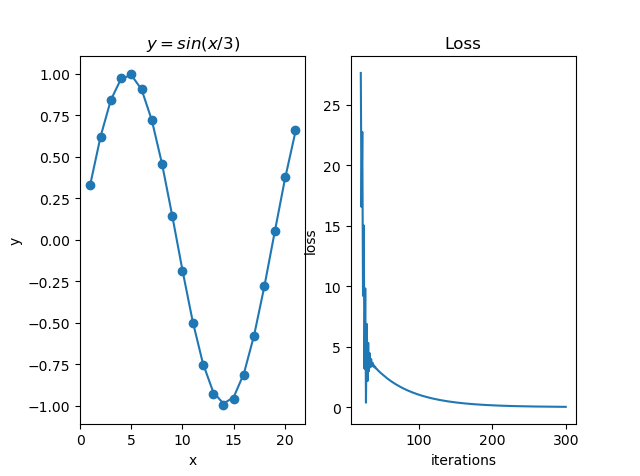
拟合函数:y=sin(x/3)
数据集:本地随机生成
编程语言:Python那天舍友找到我,问我搞不搞BP神经网络,于是我就自闭了两天。现在,一个清晰的图像呈现在我眼前,它是拟合众多实例中的一个。
注意:本文不对BP的原理做出详尽的解释,具体推导过程请参阅[1],这里只对模型进行编程化表示,想要代码的直接翻到文末,因为过程主要是我对机器学习课程的理解,似乎有点冗长,并存在未知的问题,但代码可以运行,有需要的小伙伴可以下载。
在本文开始之前,你需要了解:
一、线性代数基础
二、Python基础(含numpy、matplotlib.pyplot、random库)
三、高等数学基础(主要含链式求导法则)
四、线性回归基础
五、深度学习基础(BP神经网络原理)
OK,我们开始快乐建模与coding!
以下述函数为例:$$y={x^2}$$
一、模型的建立与表示
我选择了最简单的神经网络模型,即一个输入层,一个隐藏层,一个输出层,激活函数[2]选择最简单的y=x,因为我们要拟合函数。如图:
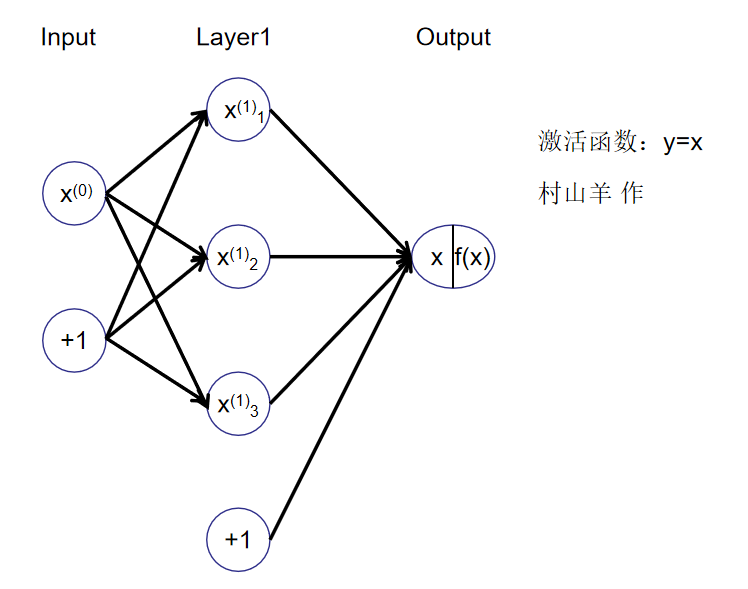
偏置项与之前的回归模型不同,这里独立出来,之后会提到。
二、数据初始化、矩阵化与正向传播
这里采用了连续间隔为1的x离散图,x∈[-10,10],设
$$y={x^2+rd}$$
其中rd为-5/3到5/3的随机数,用于制造噪点。
假设数据有n列(这里n为21),矩阵表示$X^0$,有:
$$
X^0=
\begin{pmatrix}
x_{1} \\
x_{2} \\
\vdots \\
x_{n} \\
\end{pmatrix}
$$
MathJax我打不出来同时带上下标的公式QAQ 相同地,$Y$表示为:
$$
Y=
\begin{pmatrix}
y_{1} \\
y_{2} \\
\vdots \\
y_{n} \\
\end{pmatrix}
$$
权重阵${θ_1}$为:
$$
\begin{pmatrix}
θ_1^1 & θ_2^1 & θ_3^1
\end{pmatrix}
$$
权重阵${θ_2}$为:
$$
\begin{pmatrix}
θ_1^2 \\
θ_2^2 \\
θ_3^2 \\
\end{pmatrix}
$$
公式有点问题,只能用上标表示行,以下标表示列,向量要以该形式表示,没有问题,这里加个猛男嘻嘻~ 两个偏置项b1,b2,分别用两个列向量表示(初值置为1):
$$
\begin{pmatrix}
b_1^1 \\
b_2^1 \\
\vdots \\
b_n^1 \\
\end{pmatrix}
\begin{pmatrix}
b_1^2 \\
b_2^2 \\
\vdots \\
b_n^2 \\
\end{pmatrix}
$$
值得注意的是,该处xθ为矩阵相乘,最后是一个3×3的矩阵:
$$
\begin{equation}
\begin{split}
xθ_1+b1= \\
\end{split}
\end{equation}
$$
$$
\begin{pmatrix}
x_{1}^1 & x_{1}^2 & x_{1}^3 \\
x_{2}^1 & x_{2}^2 & x_{2}^3 \\
\vdots & \vdots & \vdots \\
x_{n}^1 & x_{n}^2 & x_{n}^3 \\
\end{pmatrix}
$$
这个矩阵很有意思,他的每一个列向量表示一个神经元,我们的所有节点均为这样的列向量,如果你按我的思路推导,就能得出以上结论。
继续输出(正向传播),得到output层:
$$
\begin{equation}
\begin{split}
xθ_2+b2=
\end{split}
\end{equation}
$$
$$
\begin{pmatrix}
y_1^{‘} \\
y_2^{‘} \\
\vdots \\
y_n^{‘} \\
\end{pmatrix}
$$
至此,正向传播构建完毕我快给公式搞疯了
三、误差与梯度
根据吴恩达课程所教内容,每层误差为:
$$
\begin{equation}
\begin{split}
δ^{2}=output-Y \qquad (1)
\end{split}
\end{equation}
$$
$$
\begin{equation}
\begin{split}
δ^{1}=δ^{2}θ^T \qquad (2)
\end{split}
\end{equation}
$$
真的,这公式有点丑,但我才刚刚上手MathJax,不用在意~ 这里的(2)与吴恩达不同,因为我们使用了y=x作激活函数,导数就为1,而吴恩达的为sigmoid激活函数,所以有所不同。
好了,到求梯度环节!
根据链式求导法则[3],有
$$
Δ^{(2)}:=\frac{1}{m}(Δ^{(2)}+{layer1}^Tδ^{2}) \\
Δ^{(1)}:=Δ^{(1)}+x^Tδ^{1}
$$
$Δ^{(1)}$与$Δ^{(2)}$即为每层连接矩阵的梯度向量,这里的$Δ^{(k)},k=1,2$刚开始时置为0,我在编程中使用了笨方法,即用两行代码表示两个梯度项,没有如吴恩达他老人家展开成一列向量,我这么做的坏处就是不易更新与维护,whatever,我会继续更新算法的。
四、梯度下降与循环
在这里,我使用了最传统的梯度下降法,没有使用高级算法(造业余轮子一百年),有:
$$
θ_1:=θ_1-aΔ^{(1)} \\
θ_2:=θ_2-aΔ^{(2)}
$$
其中a为学习率,取一<1的数,我一般取0.1、0.3、0.003等等,这是为了防止梯度爆炸[4],不瞒你说,我在实际运行中出现过很多次梯度爆炸。
大功告成!但是等等,我们似乎漏掉了偏置项!根据链式求导,我们轻松地求出了偏置项的梯度下降公式为:
$$
b1=b1-aδ^{1}
b2=b2-aδ^{1}
$$
切记!这里的梯度下降是直接对误差δ求的,不是对Δ!
之后,我们做一个循环,这与回归类型一致,不再赘述。
五、运行结果
先上一张运行效果图!(btw,我加入了误差和多图表示,使得程序与上述有些不同,但你应该能分辨吧hh)
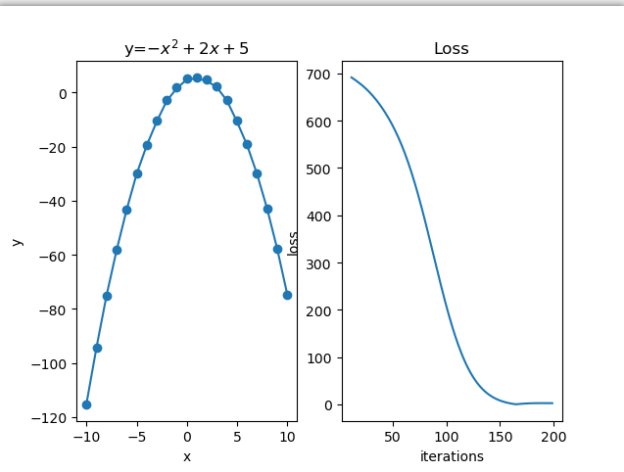
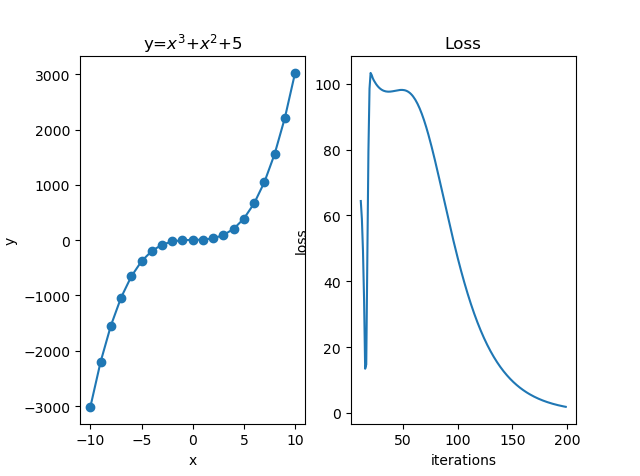
左边的图为散点拟合图,右边为随迭代次数升高的误差,可以看到误差在降低。有些拟合函数的误差并没有这么完美,它们是先降低后升高再降低的,就像这个:
{kind=link}
除此之外,还有许多有趣的图片,你可以点击下方链接来查看它们:
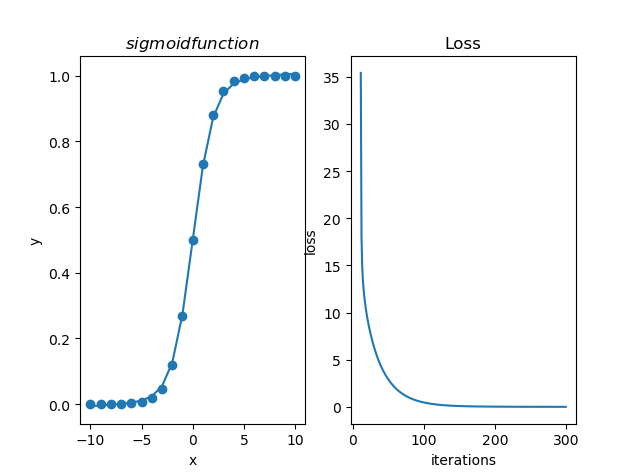
点击查看拟合sigmoid图
点击查看拟合简单正弦函数图
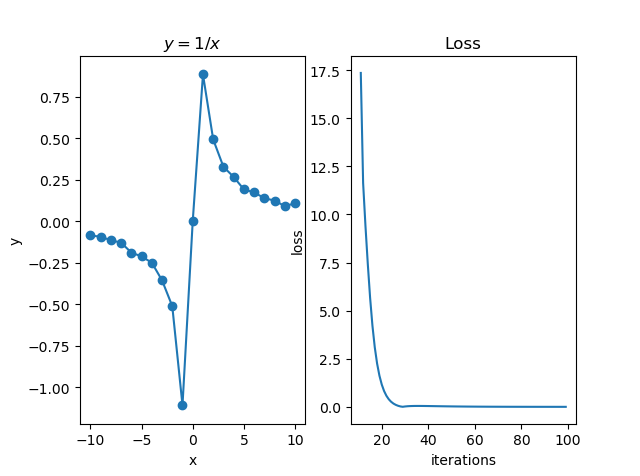
点击查看拟合过原点反比例函数图
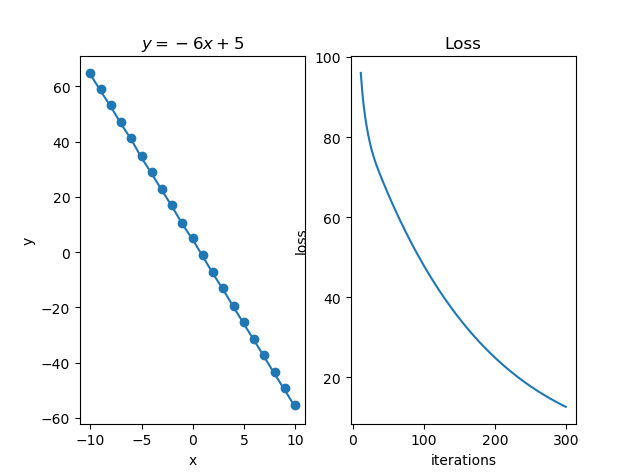
点击查看拟合一般一次函数图
{kind=link}
{kind=link}
{kind=link}
{kind=link}
你可以在下载项的源代码中关掉动画项,如果你的计算机算力不强的话(具体请见源代码注解)。
好了,今天就到这吧,我们分类问题见!
六、参考资料与下载项
1、参考资料
[1]周志华.机器学习[M].清华大学出版社:周志华.2016-1-1
[2]激活函数
[3]链式求导法则
[4]梯度消失与梯度爆炸
2、下载项