在上篇文章中,我分析了一元线性回归的可行性与应用实例。
在这篇文章中,我将对一元线性回归的模型进行扩展,从而实现多元线性回归模型。
从matlab中线性回归核心代码:
1 | for i = 1:k, |
看出,A的本质是一个行数与θ(j)个数相同,列数为1的向量,该向量与学习速率相乘后被相应的θ相减从而被迭代,可以预见:A的大小与x的大小无关,故可以扩展x的元数,形成多元的线性回归算法。
以下是模型要点:
①注意原始数据与矩阵数据的不同:因为多元函数有一项为常数,进行矩阵乘法时,需要对x(n×m)的左侧进行增扩一个n×1的列向量,形成的x1为n×(m+1),如下图:
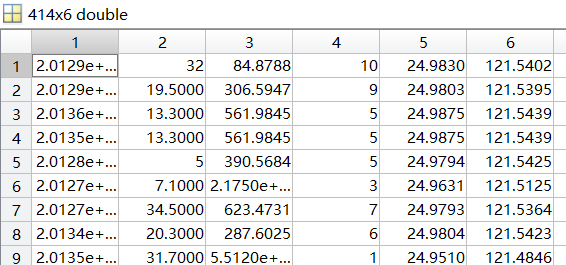
(原始数据集,导出为414×6的矩阵)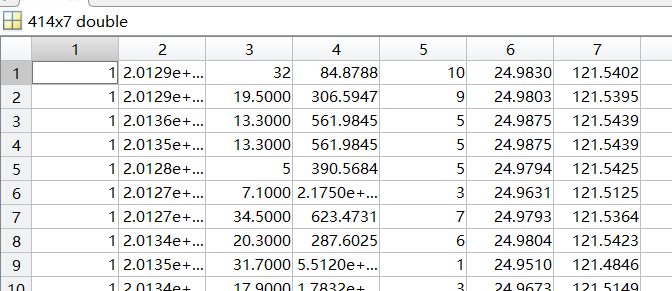
(左侧增扩,形成414×7的矩阵) ②由于数据的不同性,学习速率必须做出相应的调整,以上的数据用学习速率为0.00000001经过迭代10000次后收敛,故将学习速率α(matlab中为a)单独做一个变量
③增扩矩阵与原始矩阵间必须有如①的对应关系,但是如果直接改变原始矩阵的列数,则下次重新运行程序时会将矩阵左侧再加一个列向量,导致运行失败,故一定要有一个矩阵(此处称为x1)继承并对应增扩矩阵。
④变量初始化问题:θ列向量在开始时应该设为0向量,以便后续操作,有语句:
1 | theta = zeros(size(x1,2),1); |
将θ设为0向量。
⑤迭代次数与学习速率:由于数据的特异性,需要对每一个具体分析的数据集调整不同的迭代次数(iterations)和学习速率(a),测试后函数不再发散即可。
测试案例(数据来自kaggle):
[Real estate](/download/datasets_88705_204267_Real estate.csv”)
工作区数据(运行后):
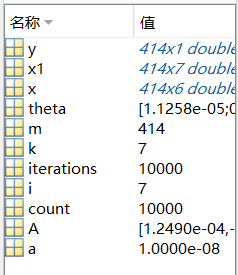
结果(a=0.00000001,iterations = 10000时):

测试样例正确性代码(取x1的某一行与θ相乘得到y1,看每一个y1结果是否与y近似)
:
1 | for k = 1:414, |
由此,得到散点图:
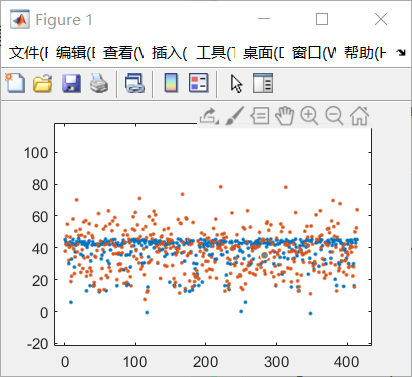
(蓝色部分为拟合的y1,红色部分为原始数据y)
易见,拟合情况较好(不过由于该数据点分部较为分散,有较多y未能很好拟合)
最后,附上代码实例: