本文将从高度数学与线性代数角度来阐述线性回归算法的可执行性,并给出完整实例(matlab编写)。
这里是声明部分:本文章使用markdown语法编写,因为不懂如何插入公式,故使用英译法表示希腊字母,矩阵元素以中国规定的行列表示法表示。
Part Ⅰ
代价函数
高中的伟大导师蒋(以下简称jml)曾经讲过初级的误差估计(一元函数),在高等数学中
我们将对误差估计做出更加精确化的描述(虽然我高中数学非常菜)。
假设有一组数据集,分别用x和y表示横纵坐标,那么在坐标轴上可以得到一组离散的坐标点:
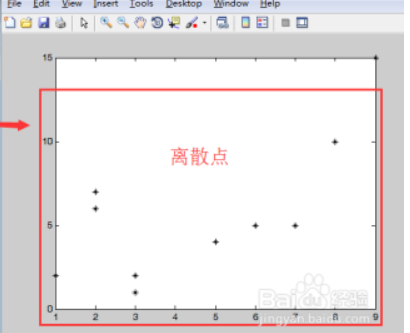
(图片来自于百度) 要拟合这些点,也就是得到所谓得“拟合函数”,我们需要两个参数,这里称作theta1和
theta2,也就是jml在高中所说的y=kx+b中的b与k。
我们先不考虑如何得到这两个参数,先考虑拟合情况好不好,那么,需要一个函数来判定拟合情况,这个函数在高中有接触过,就是把拟合函数在x处的y’与原本的y作差后平方,接着对每一个算出每一个y’,求和,然后再除以2倍的样本值(至于为什么是2倍的样本值,这是因为之后要讲的梯度下降需要对每一个变量求偏导)
如果具体到公式,以h表示拟合函数,那么:
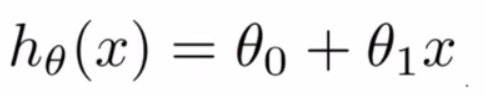
代价函数J为:
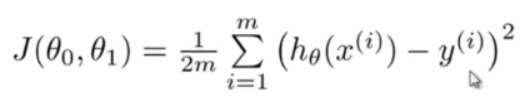
此时要想知道拟合情况,只要看J函数的值与0的距离,离0越近,拟合越好。
用matlab表示该函数,即
1 | function J = Jcost(X,y,theta) |
测试,得到的结果正确。
Part Ⅱ
梯度下降
现在我们知道如何量化表示拟合函数的拟合情况,但是重要的问题还是没有解决,即如何求出拟合函数。在吴恩达的课程中提供了两种方法,这两种方法均会介绍,但我们着重讲述第二种方法,即梯度下降法。
①超定线性方程组与最小二乘解
考虑一个方程组(Ax=b),它由n个未知数组成,却有大于等于n个的方程,这样的方程组称为超定线性方程组。这种方程组经过数学推导(从略)后可以得到以下的式子:
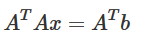
x就为Ax=b的最小二乘解。原方程组可能无解,向量x的各项带入方程组,使得与方程组中各方程的解最接近(也就是误差最小),这时的解称为最小二乘解。
②梯度下降法
同济高等数学在偏微分一章讲过了梯度下降法的具体内容,按百度百科所说,
“梯度下降是迭代法的一种,可以用于求解最小二乘问题。”
我们知道,代价函数J拥有它的最小解,这个解不一定能用数学方式表达出来,而数学家想出了一种办法,可以有效地让代价函数收敛到它的极小值(不是最小值,所以梯度下降法具有不可避免的误差),具体如下:
一、初始化变量
二、对函数J求一个变量的偏导(这里与之前的1/2m呼应,因为求导后平方项会多出一个2,刚好消去,同时,此步是为了求出在初始化条件下在某一点函数的切线,不过我偏导的几何没有弄清,有说错的地方请指正)
三、给予J的偏导一个速率α,这是为了让J的偏导能向该方向“迈开步子”,“步子”决定了J的收敛时间与收敛区域(α过小,则收敛时间越长;α越大,则收敛区域越大,甚至可能不收敛)
四、将对J求偏导的那个变量减去α×J’,得到新的变量(这一步称为对变量的一次迭代)
五、对其他的变量做上述的变化一到四,当所有的变量均完成后一个循环结束,进入下一个循环
六、迭代多次后,得到最小二乘(或近似)解
一元的梯度下降公式如下:
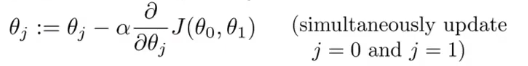
(来自吴恩达:机器学习,网易公开课)PartⅢ
线性回归模型
现在你已经了解了梯度下降的原理,可以结合线性代数的知识来统一模型并加以应用。我从Kaggle上下载了一个二元数据集(300个数据对),他差不多长这样:
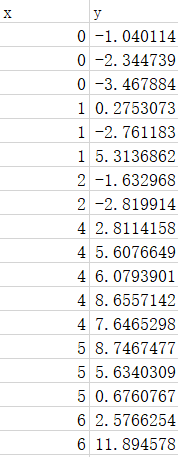
图中的数据有经过升序排列,与原数据不太一样。
如何利用已有的模型编程解决这些数据的拟合?经过吴老师的启发,我们把二元参数(即θ1、θ2)看作一个列向量θ=[θ1;θ2],(注意,θ’表示为θ的转置)把上图中的x与y分离,成为两个单独的列向量,同时将x的左侧扩充一个列向量,成为如下样子:
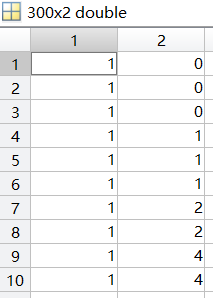
这样,当我们算(θ’x’)’-y(化简得xθ-y)时就是算出了残差,带入梯度下降公式同时可以得到(以下部分有经过化简与改良,比较难理解):
1 | for i = 1:k, |
这里的A表示一个2×1的行向量,k为θ的列数(即为2),m为数据对数(这里为300对),sum()为求和函数,而sum函数中的式子表示:
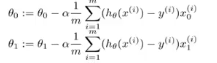
x(i)0为x矩阵中第1列第i行的元素(全为1);
x(i)1为x矩阵中第2列第i行的元素(为0 0 0 1 ……)。
这样,我们就得到了模型的核心算法,接下来就是迭代了,代码略。
你可能会发现该模型不仅适合于二元线性回归模型,扩充参数矩阵后仍然适用,但那要等到我下一次更新了。
最后,放出点的离散图与回归过程与回归结果图:
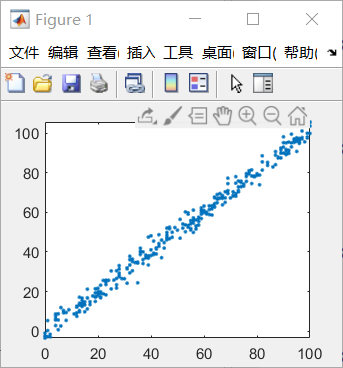
(数据集的离散图)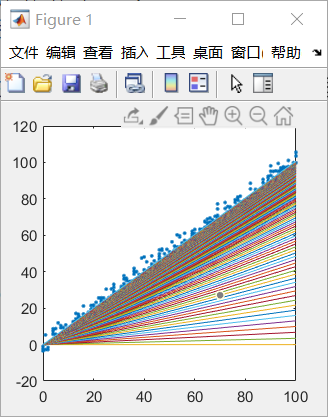
(迭代次数为1000时得到的线性回归图(方向由水平直线向散点图偏移))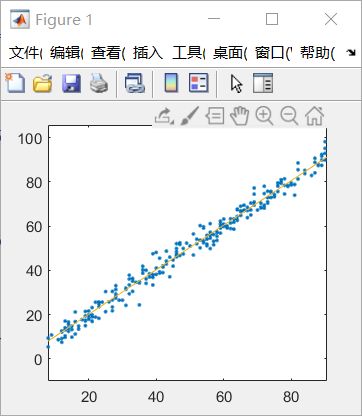
(最终的线性回归图,线比较小容易忽视)附上有关数据与程序下载链接: